
Classes as Decorators of Methods in Python
I have had some trouble to figure out how to use a class as a decorator for a method (as opposed to a decorator for a function). Here is a script that prints some useful information about what is called when and with what parameters.
#!/usr/bin/env python
print "Classes as Decorators of Methods\n"
print "-----Parsing dec"
class dec(object):
def __init__(self, a):
print "----- dec init"
print type(a)
print "decorated method: ", a.__name__
self.a = a
def __get__(self, inst, cls):
print "-----dec get"
self._inst = inst
self._cls = cls
return self
def __call__(self, p):
print "-----dec call"
print type(self)
print type(self._inst)
print type(self._cls)
return self.a(self._inst, p.upper())
print "-----Parsing C"
class C(object):
def __init__(self):
self.X = "Hello"
@dec
def run(self, p):
print p,
print self.X,
return "world"
if __name__ == "__main__":
print "-----Object creation"
c = C()
print "-----Object method call"
print c.run("This is a decorator ")
This produces the following output:
Classes as Decorators of Methods
-----Parsing dec
-----Parsing C
----- dec init
type 'function'
decorated method: run
-----Object creation
-----Object method call
-----dec get
-----dec call
class '__main__.dec'
class '__main__.C'
type 'type'
THIS IS A DECORATOR Hello world
In contrast: functions as decorators for functions
#!/usr/bin/env python
print "--- Parsing dec"
def dec(f):
print "--- Run dec"
print f.__defaults__
def x(*args, **kwargs):
print "--- Run x"
print f.__name__
print args
print kwargs
f(*args, **kwargs)
return x
print "--- Parsing foo"
@dec
def foo(a, b=3):
print "--- Run foo"
print a, b
print "--- Calling foo"
foo(1)
print "--- Calling foo"
foo(2, 4)
Which outputs:--- Parsing dec
--- Parsing foo
--- Run dec
(3,)
--- Calling foo
--- Run x
foo
(1,)
{}
--- Run foo
1 3
--- Calling foo
--- Run x
foo
(2, 4)
{}
--- Run foo
2 4
 .
. Spend the day fiddling around with ROOT
Read this, if you think that using ROOT and C++ for scientific analysis is a good idea!If you start with scientific data analysis or if you are looking for a framework to build the software of your next-generation experiment: scipy/numpy seems like a good idea!
But please don't use ROOT. Please...
Django Internationalization
UDPATE: please check the djangoproject, because the situation is much better now...Today I realized that the django way of internationalization is not as good as I had thought. Here are two areas where it could be improved:
The models
Django has no default way of translating fields in models. This is a known shortcoming and was addressed in many plugins (transdb, transmeta, multilingual, multilingual-model, translate, ...) and in a Google Summer of Code project by Marc Garcia.
As I see it, the translation of any kind of data should not be in a seperate table or in a metaclass. Why? Because translation should not be the way to think in the first place. If you have a piece of information that is not universally understandable (like an photograph), than you can assign a language or culture to that information. If your site should be available in several languages, then there is no good reason why one language should be superior (and allowed in the model), while other languages are inferior (and have to go into a translation table). So there is no translation of a first, superior string but there is a piece of information in different, equally important languages.
So, with regard to this poll, the only good option would be to state "this field is language specific" and django should create a field for every supported language (mainly like multilingual-model).
The admin interface should display these fields and a bonus would be to be able to create a report based on the missing translation fields.
The urls
But there are other fields where internationalization is also important and where I couldn't find any plugins or snippets. It's the url resolution. Your apps should have human-readable urls that don't change over time. Suppose you have this url in your shop: "/smartphone/linux/N900" and suppose that "smartphone" is a category that was not planned when the shop was planned but rather entered in the admin as a (translatable) categorization of a specific phone. Now if you want to make this translatable, you have to create a pattern like
"(?P
but how is that supposed to be distinguished from
"(?P
if these things should also be translatable? So the point is: the regular expressions in the url resolution mechanism are not translatable (if the strings are dynamical db content).
What could be done?
The could be an url manager that can receive signals about a change in the urls patterns. And there should be an attribute (db-field, function, ...) in every model or view which can take translatable fields as parameters and create and update the corresponding urlpatterns.
A FITS thumbnailer for Thunar
If you work in Astronomy, you will likely have a lot of fits files lying around. Although the FITS format is absolutely not an image-only format, I would still like to see a preview in my filemanager if there is an image encoded in the file. The standard thumbnailers for Xubuntu don't do this, so here is how to create your own:- create a desktop file that describes, what your thumbnailer does:
/usr/share/thumbnailers/fits-thumbnailer.desktop[Desktop Entry] Version=1.0 Encoding=UTF-8 Type=X-Thumbnailer Name=FITS Thumbnailer MimeType=image/x-fits;image/fits;application/fits; X-Thumbnailer-Exec=python /usr/lib/thunar-thumbnailers/fits-thumbnailer.py %i %o %s
- create the thumbnailer script under:
/usr/lib/thunar-thumbnailers/fits-thumbnailer.py#!/usr/bin/env python import pyfits import matplotlib.pyplot as plt import sys try: infile = sys.argv[1] outfile = sys.argv[2] except: exit(1) try: size = sys.argv[3] except: size = 256 hdul = pyfits.open(infile) data = None # Is the primary HeaderDataUnit an image with data? if (hdul[0].header["NAXIS"] != 0): data = hdul[0].data else: # The primary had no data, so we search for the first image! for hdu in hdul[1:]: if (hdu.header["XTENSION"] == "IMAGE"): data = hdu.data break if data != None: plt.imshow(data) plt.savefig(outfile, transparent=False, format="png") - regenerate the thumbnailer cache:
/usr/lib/thunar/thunar-vfs-update-thumbnailers-cache-1
See it in action:
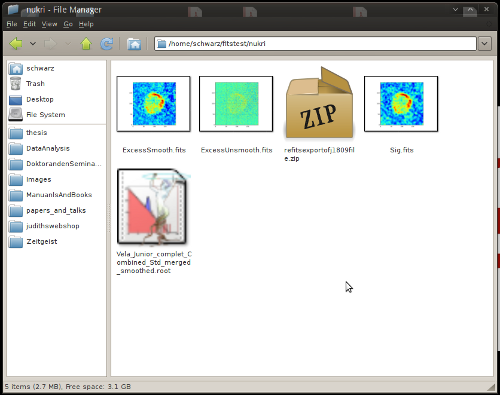
There are actually a lot of cases, where this will not work, it will not take WCS into account and is in general not very sophisticated, but it works for me (TM). For more information about Thunar thumbnailers see:
Customizing Thunar
Additional thunar thumbnailers
Freedesktop thumbnailer spezification
Freedesktop desktop-entry spezification
Eee PC 901 go: Nice hardware, bad software
Yesterday I got my new Eee PC 901 go with 16GB ssd harddrive and Linux. The battery lifetime is great, the hardware in general is really nice.But the software really really sucks. I have no idea why Asus is doing this (actually, I have an idea).
Ok, so what is the problem with that software thing on the Eee PC?
The first impression is that they tried their best to make it look like XP. This IS annoying. With all the innovation that they could have made, they chose to imitate the one system that Linux users don't want to see. The second impression is that the software I want is not there, that updates are missing (2009/06 and still Firefox 2.0 ????) and that the only configuration Asus wants you to do is changing the background color. One thing to note is that the screen is really small and a small window theme (icewm is used along with kde and gnome applications) would be good. Instead a big theme is used along with a big cursor and big fonts. There are signs of a full desktop mode (a start script, tutorials on the internet), but the Asus homepage states very clearly: Only one desktop mode is available.
So I guess that I will investigate further, if eeebuntu isn't much better. And the next time I will try to buy at system76 , if they start to deliver to Germany ...
Note to self: Latex and Labels
In a Latex figure environment, the \label command has to follow the \caption command. Otherwise referencing the figure will result in the section number (where the figure appeared) to be printed. Sometimes Latex is not very user friendly...
\begin{figure}[!th]
\centering
\includegraphics[width=2.5in]{some_filename}
\caption{some caption}
\label{fig:some_image}
\end{figure}

Emacs as a latex environment
I use the AUCTex mode in Emacs, which has lots of useful features. Here is a mix of commands and additions that help me improve the Emacs-Latex experience:RefTex (actually you will already use this if you use AUCTex mode), Greek Emacs input, PDFSync and Orgmode tables.
RefTex
There is much to say about reftex But I'll just show the two commands that I use regularly:C-c =This will open a buffer where you can navigate through your document's toc.
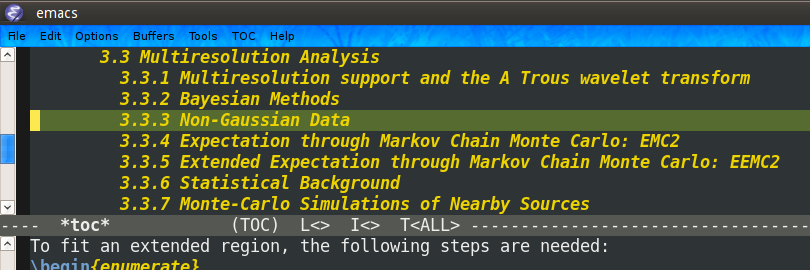
This comes very handy for large projects like PhD thesis :-). With python I use something like outline mode for roughly the same purpose, but this is perfect for my latex documents.
The other shortcut I use is:
C-c [This command will ask you for your citation style
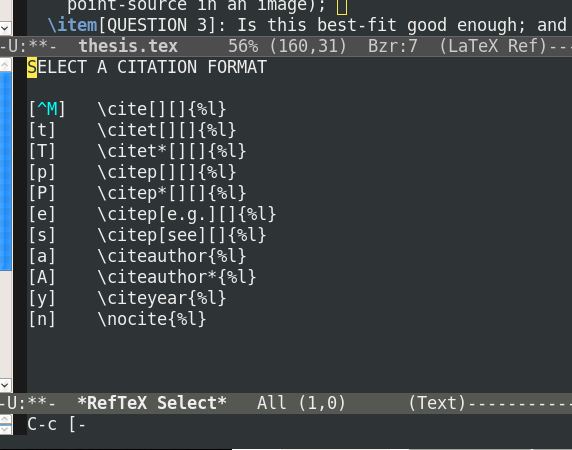
and for a regulare expression for searching your bibtex file to find the reference.
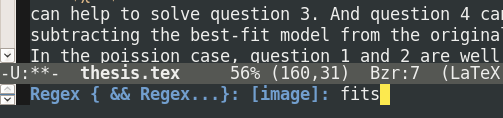
Then you can navigate through the matching references and choose the one that you want.
With a single bibtex file containing about 1000 references this feature is very handy.
Xelatex for greek input
If you are using texlive / xetex, then you have full utf-8 support built-in. Now you need a way to use it :-) If you write in a language other then english, you probably already use this feature. Just typing
äöüß
instead of
\"a\"o\"u\ss{}
is already good. But being able to also type:
$αβγ = 3μm$
instead of
$\alpha\beta\gamma = 3\mum$
is really a good thing, both for readability and for typing speed.
Update: actually it's not that simple. But it got simpler with TexLive 2009. I have something like this in the preamble of my documents:
\usepackage{mathspec}
\setmainfont[Mapping=tex-text]{CMU Serif}
\setsansfont[Mapping=tex-text]{CMU Sans Serif}
\setmathsfont(Greek,Latin){CMU Serif}
\setmathsfont(Digits){Neo Euler}
To insert greek characters in emacs, just type:
C-\ greek RET
From then on, the
C-\
will switch between greek input and your normal input.
PDFSync
Sometimes in larger documents, you want to jump directly from a line in your latex file to the corresponding line in the pdf file. With pdfsync and xpdf, this is possible (note that with TexShop the other way is also possible, but not with emacs at the moment). In you Latex file, insert the following:
\usepackage{pdfsync}
Now just type:
C-c C-v
and the line will be displayed in xpdf. Nice.
OrgMode Tables
The Emacs Org mode is a great mode for table editing (and other things). The table editing mode can be called separate from the complete Org mode, which is a great tool for example for Latex, where the table editing is something very unpleasant! The following work flow helps a lot, but check out the full example here for more advanced options: OrgMode ManualLet's start with a Latex file with the comment package (the org mode table is within a comment environment, so your latex does not get messed up!):
\documentclass{article}
\usepackage{comment}
\begin{document}
Hallo!\\
\end{document}
Then type:
M-x orgtbl-mode
M-x orgtbl-insert-radio-table
This will ask you for a table name, let's say: atesttable
Now the document looks like this:
\documentclass{article}
\usepackage{comment}
\begin{document}
Hallo!\\
% BEGIN RECEIVE ORGTBL atesttable
% END RECEIVE ORGTBL atesttable
\begin{comment}
#+ORGTBL: SEND atesttable orgtbl-to-latex :splice nil :skip 0
| | |
\end{comment}
\end{document}
And then you can change the table using the great OrgMode capabilities!
Once you have done this, type
C-c C-c
This will update the latex table to something like this:
\documentclass{article}
\usepackage{comment}
\begin{document}
Hallo!\\
% BEGIN RECEIVE ORGTBL atesttable
\begin{tabular}{rll}
Times [sec] & Names & something else \\
\hline
3 & John & hi \\
4 & Elisa & ho \\
5 & Nobody & hiho \\
& & \\
\end{tabular}
% END RECEIVE ORGTBL atesttable
\begin{comment}
#+ORGTBL: SEND atesttable orgtbl-to-latex :splice nil :skip 0
| Times [sec] | Names | something else |
|-------------+--------+----------------|
| 3 | John | hi |
| 4 | Elisa | ho |
| 5 | Nobody | hiho |
| | | |
\end{comment}
\end{document}
That's it. My current setup and usage of Emacs as a Latex IDE.
OpenOffice
Why do I even try to used it again and again?OpenOffice 3 crashed for the third time today. I really should have made that presentation with Latex-Beamer!
Oh and by the way: If I write μController I don't mean Mcontroller, AutoCorrect seems to think different...

Precision of float calculations
Given that a and b are positive, the calculation:
But is this true in computer languages?
a:1.2345678e-30
b:5.5889944e-28
The real result is: 6.89999252062032 e-58
What do the following programs tell me?
C
#include <math.h>
#include <stdio.h>
int main(){
double a = 1.2345678e-30;
double b = 5.5889944e-28;
double c, d;
c = a * b;
d = exp(log(a)+log(b));
printf("a * b = %.20e \n", c);
printf("exp(log(a) + log(b)) = %.20e \n", d);
return 0;
};
output:
a * b = 6.89999252062031977189e-58
exp(log(a) + log(b)) = 6.89999252062023345995e-58
The real result is: 6.89999252062032Python
import math a = 1.2345678e-30 b = 5.5889944e-28 print "----------math----------" print "a * b = %s" % repr(a*b) print "exp(log(a) + log(b)) = %s" % repr(math.exp(math.log(a)+math.log(b))) import mpmath mpmath.mp.dps = 20 a = mpmath.mpf(1.2345678e-30) b = mpmath.mpf(5.5889944e-28) print "---------mpmath---------" print "a * b = %s" % repr(a*b) print "exp(log(a) + log(b)) = %s" % repr(mpmath.exp(mpmath.log(a)+mpmath.log(b)))
----------math----------
a * b = 6.8999925206203198e-58
exp(log(a) + log(b)) = 6.8999925206202335e-58
---------mpmath---------
a * b = mpf('6.8999925206203201922352e-58')
exp(log(a) + log(b)) = mpf('6.8999925206203201919869e-58')
The real result is: 6.89999252062032Scheme
(define y 0.00000000000000000000000000055889944)
(* x y)
(exp (+ (log x) (log y)))
output:
6.89999252062032e-58
6.899992520620233e-58
R
6.899992520620233e-58
gcalctool
Not exactly a language, but interesting: the result is 6.89999252062032e-58 for a*b.Note, that the standard windows calculator also prints the exact result.
So what is the result:
| Language | Results |
|---|---|
| c: |
6.89999252062031977189 e-58 6.89999252062023345995 e-58 |
| python (math): |
6.8999925206203198 e-58 6.8999925206202335 e-58 |
| python (mpmath): | 6.8999925206203201922352 e-58 6.8999925206203201919869 e-58 |
| scheme: |
6.89999252062032 e-58 6.899992520620233 e-58 |
| R |
6.89999252062032e-58 6.899992520620233e-58 |
| gcalculator and windows calculator: | 6.89999252062032 e-58 |
| the real result: | 6.89999252062032 e-58 |
Xfce 4.6 released
You might have read it already, but today the Xfce team released Xfce 4.6!Congratulation to the developers.
Take a look at the new features here: Tour
Scientific python packages
I use these packages regularly:- python 2.5 (http://www.python.org)
- numpy (http://www.scipy.org/Download)
- scipy (http://www.scipy.org/Download)
- matplotlib (http://sourceforge.net/projects/matplotlib)
- pyfits (http://www.stsci.edu/resources/software_hardware/pyfits/Download)
- kapteyn (http://www.astro.rug.nl/software/kapteyn/)
- mayavi2 ( http://code.enthought.com/projects/mayavi/docs/development/html/mayavi/installation.html)
- python-sao (http://code.google.com/p/python-sao/)
- pymc (http://code.google.com/p/pymc/)
To be done... part 2: Meta-information
My Problem:
I have a lot of unsorted scientific papers! Their filenames don't resemble their titles and they are stored in a bunch of places. I tend to download them as I search the internet for papers that help me with a problem and sometimes I even DownThemAll.
Weeks, month later, I try to find the *one paper* that was so interesting and cite it via BibTex in my Latex file. But I can't remember the filename, title, author, year or journal (in any combination).
Or I see a paper, know that I read it, but can't remember if it was that good...
Possible Solution:
Using a search engine (Tracker), a bibliography manager (Referencer) and a file manager (Thunar).
With Thunar, I can mark files as interesting.
With Tracker I can search the text of a document and tag it.
With Referencer I can tag a paper and export the meta-information to a Bibtex file.
Why I'm still unhappy:
It seems that Tracker, Referencer and Thunar don't use the same location to store meta-information about the documents. They all seem to use different databases.
I would have to write a plugin for two of them to get the three of them working together.
Not good.
Using numdisplay
Numdisplay is one of the cool python astronomy packages that lack documentation! What I want to do is display an image from the python shell (easy and well documented) and this image shall contain WCS information, because otherwise I could as well use matplotlib (really hard and NOT documented).What I know so far:
- open ds9 with the following command:
ds9 -unix "/tmp/.IMT3"
- in the python shell create an UnixImageDisplay
uid = numdisplay.displaydev.UnixImageDisplay("/tmp/.IMT3") - don't really know how to continue ... the wcs stuff seems not to work the way I expect ...
Next try, this time with python-sao:
import pysao ds9 = pysao.ds9() ds9.view(hdul[6])
Much better :-)
Python, Astronomy and Maps
Update: the solution is here: KapteynUpdate 2: there is also a new package that I have not tested, but that seems to be good: APLpy
Update 3: and now there is also: pywcsgrid2
You might want to look at the following site for more up to date information: astropython
Python is a good language for scientists. It basically replaces proprietary software like IDL, Matlab or SAS. What it lacks at the moment is an easy way to display astronomical data saved as fits files containing WCS information.
WCS information standardizes the transformation between pixel coordinates and world coordinates (e.g. position in the sky). There is a good library, pywcs, that deals with this information.
Matplotlib, a good choice for plotting data with python, includes Basemap, a toolkit to display maps (of the earth) in various projections. What is missing is a link between these two!
| Basemap name | FITS Code [WCS] | Names |
|---|---|---|
| AZP | Zenithal perspective | |
| SZP | Slant zenithal perspective | |
| Gnomonic Projection | TAN | Gnomonic |
| Stereographic Projection | STG | Stereographic |
| SIN | Slant orthographic | |
| ARC | Zenithal equidistant | |
| ZPN | Zenithal polynomial | |
| Lambert Azimuthal Equal Area Projection | ZEA | Zenithal equal area |
| AIR | Airy | |
| CYP | Cylindrical perspective | |
| CEA | Cylindrical equal area | |
| Cassini Projection | CAR transverse case | |
| CAR | Plate carree | |
| Miller Cylindrical Projection | CAR with unequal scaling | |
| Mercator Projection | MER | Mercator |
| Transverse Mercator Projection | MER transverse case | |
| Oblique Mercator Projection | ||
| Equidistant Cylindrical Projection | ||
| Sinusoidal Projection | SFL | Sanson-Flamsteed |
| PAR | Parabolic | |
| Mollweide Projection | MOL | Mollweide |
| AIT | Hammer-Aitoff | |
| COP | Conic perspective | |
| Albers Equal Area Projection | COE | Conic equal-area |
| Equidistant Conic Projection | COD | Conic equidistant |
| COO | Comic orthomorphic | |
| Lambert Conformal Projection for sperical earth = COO | ||
| BON | Bonne's equal area | |
| Polyconic Projection | PCO | Polyconic |
| TSC | Tangential Sperical Cube | |
| CSC | COBE Quadrilateralized Spherical Cube | |
| QSC | Quadrilateralized Spherical Cube | |
| Azimuthal Equidistant Projection | ||
| Orthographic Projection | ||
| Geostationary Projection | ||
| Robinson Projection | ||
| Gall Stereographic Projection | ||
| Polar Stereographic Projection | ||
| Polar Lambert Azimuthal Projection | ||
| Polar Azimuthal Equidistant Projection | ||
| McBryde-Thomas Flat Polar Quartic | ||
| van der Grinten Projection |
This is my first post
I wanted to switch from blogger to my own blogging software.The main reason for this was that I wanted to do more with django and building my own blogging solution seemed to be a good start. I looked into pinax blog app and copied most part from there... And it seems to work!
What is missing:
comments- a cool admin interface (is it possible to include an emacs-nox into a django admin interface? that would be interesting...)
- file upload with automatic reference from within the blog post. Something like "attachment[1]"